Audio Processing
Great sites and courses:
[Youtube Channel] Valerio Velardo - The sound of AI: https://www.youtube.com/c/ValerioVelardoTheSoundofAI
Audio files samples:
[WAV] [STEREO]
audio_stereo.wav[WAV] [MONO]
audio_mono.wav[MP3] [MONO]
audio_mono.mp3[MP3] [STEREO]
audio_stereo.mp3[AC3] [5.1]
audio_5_1.ac3[OGG] [5 channels]
audio_5channels.ogg[FLAC] [STEREO]
audio_stereo.flac
Reading / Writing Wave files
Reading
import wave
import numpy as np
with wave.open("audio_stereo.wav", mode='rb') as wavefile:
fs = wavefile.getframerate()
ts = 1.0 / fs
nb_samples = wavefile.getnframes()
nb_channels = wavefile.getnchannels()
sample_width = wavefile.getsampwidth()
buffer = wavefile.readframes(nb_samples)
# Get the corresponding numpy dtype according to the sample width
if sample_width == 1:
sample_type = np.int8
elif sample_width == 2:
sample_type = np.int16
elif sample_width == 4:
sample_type = np.int32
elif sample_width == 8:
sample_type = np.int64
else:
raise NotImplementedError(f"Sampwidth: {sample_width}")
# Convert the byte array to the correct data type
# data.shape = (nb_samples * nb_channels)
data = np.frombuffer(buffer, dtype=sample_type)
# Split the channels
# data.shape = (nb_channels, nb_samples)
data = np.array([data[no_channel::nb_channels] for no_channel in range(nb_channels)])
If you need to read the data iteratively by chunk, you may need to use the function wavefile.setpos(pos) to set the file pointer to the specified position.
Writing
import wave
import numpy as np
import matplotlib.pyplot as plt
fs = 8000 # 8kHz
ts = 1/fs
sample_type = np.int32
nb_channels = 2
sample_width = 4
# Get the corresponding sample width according to the sample type
if sample_width == 1:
sample_type = np.int8
elif sample_width == 2:
sample_type = np.int16
elif sample_width == 4:
sample_type = np.int32
elif sample_width == 8:
sample_type = np.int64
else:
raise NotImplementedError(f"Sampwidth: {sample_width}")
# Generating audio frames
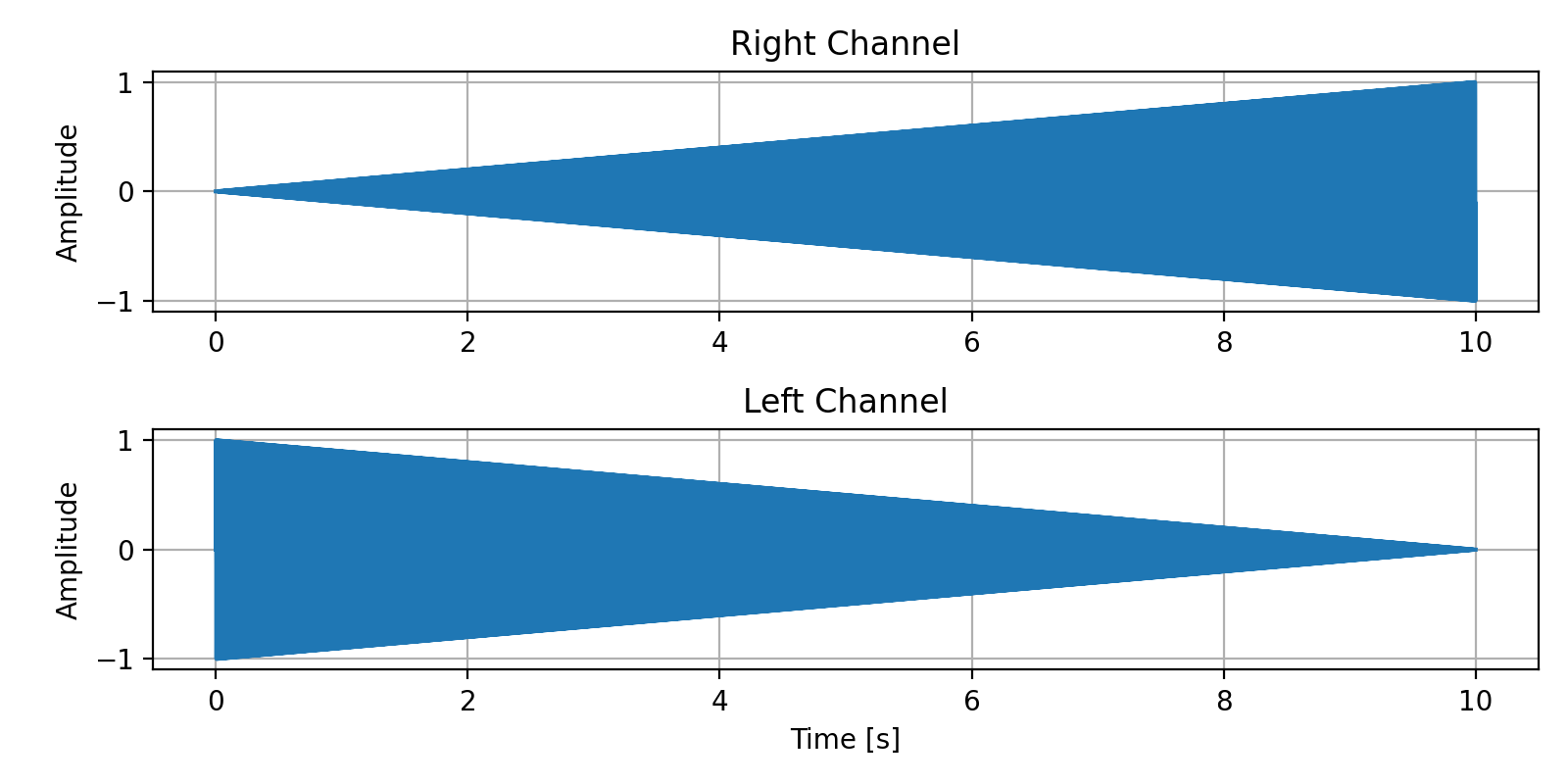
# 144Hz Sinusoide from left to right channel
N = 80000 # nb samples <=> 10 seconds at 8Khz
t = np.arange(0, N) * ts
channel_right = (np.arange(N) / (N-1)) * np.sin(2 * np.pi * 144 * t)
channel_left = (np.arange(N)[::-1] / (N-1)) * np.sin(2 * np.pi * 144 * t)
# Plot the audio samples
fig = plt.figure(figsize=(8, 4), tight_layout=True)
ax1 = fig.add_subplot(211)
ax1.grid()
ax1.set_ylabel("Amplitude")
ax1.set_title("Right Channel")
ax1.plot(t, channel_right)
ax2 = fig.add_subplot(212, sharex=ax1)
ax2.grid()
ax2.set_ylabel("Amplitude")
ax2.set_xlabel("Time [s]")
ax2.set_title("Left Channel")
ax2.plot(t, channel_left)
fig.savefig("audio_sample.png", dpi=200)
# Convert the audio channels in the right dtype
# For int32 going from -2 ** 31 to 2 ** 31 - 1
channel_right = (channel_right * (2 ** (sample_width * 8 - 1) - 1)).astype(sample_type)
channel_left = (channel_left * (2 ** (sample_width * 8 - 1) - 1)).astype(sample_type)
# Create a single flattened array
# [spl0_ch0, spl0_ch1, spl1_ch0, spl1_ch1, spl2_ch0, spl2_ch1, ...]
data = np.ravel((channel_right, channel_left), order='F')
data_bytes = data.tobytes()
# Alternatively you can do something like that
# import struct
# data_bytes = struct.pack(f'<{len(data)}i', *data)
with wave.open("audio_out.wav", "wb") as wavefile:
wavefile.setnchannels(nb_channels)
wavefile.setsampwidth(sample_width)
wavefile.setframerate(fs)
wavefile.writeframes(data_bytes)
Note
Except wave format, there is no easy and straightforward way to write audio files in python. Therefore, it’s best to write first the audio file in the wave format and convert it with tools such as ffmpeg.
Opening Other audio files formats
The best current library to open audio files other than wave files is librosa.
You can install librosa by running:
conda install -c conda-forge librosa
import librosa
data, fs = librosa.load("audio_stereo.mp3", sr=None, mono=False)
# Load an audio file as a floating point time series
# Audio will be automatically resampled to the given rate (default sr=22050)
# To preserve the native sampling rate of the file, use sr=None
# Audio will be automatically converted to mono (default mono=True)
# data.shape = (nb_channels, nb_samples)
librosa successfully read all the main audio file format I had: wav, mp3, ogg, flac, ac3
In the backgroud, librosa uses soundfile and audioread to read audio files:
audioread: https://github.com/beetbox/audioread
From the librosa documentation:
librosa uses soundfile and audioread for reading audio. As of v0.7, librosa uses soundfile by default, and falls back on audioread only when dealing with codecs unsupported by soundfile (notably, MP3, and some variants of WAV). For a list of codecs supported by soundfile, see the libsndfile documentation.
Sources:
wave official documentation: https://docs.python.org/3/library/wave.html
librosa: https://librosa.org/